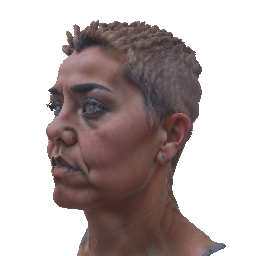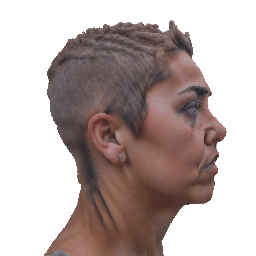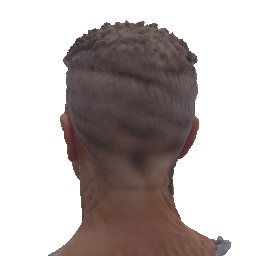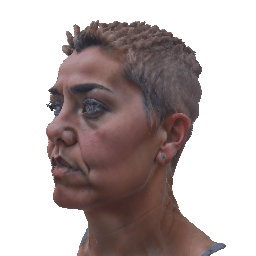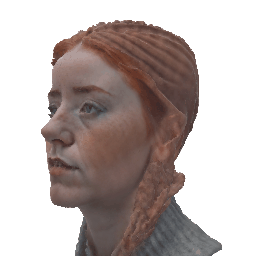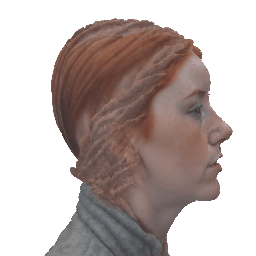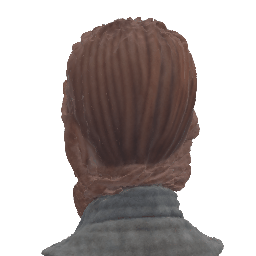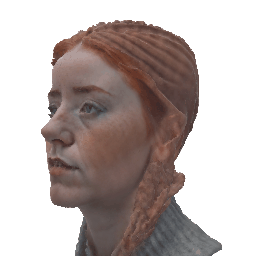Overview
Our method deploys a novel human parametric expression model in tandem with specialized geometry and albedo guidance, not only to create intricately detailed head avatars with realistic textures but also to achieve strikingly ID-consistent results across a wide range of expressions, setting a new benchmark in comparison to existing SDS techniques.
Without having to rely on 3D captured datasets that are expensive to collect and typically biased, and without being constrained on a specific geometry template, our method can be employed by a broad range of subjects, with different features such as skin tone and hairstyle.